Introducing dpkit
dpkit is a fast data management framework built on top of the Data Package standard and Polars DataFrames. It supports various formats like CSV, JSON, and Parquet and integrates with platforms such as CKAN, Zenodo, and GitHub.
dpkit is available
- as a CLI tool for Linux, macOS, and Windows - https://terminal.dpkit.app
- as a TypeScript library for Node/Deno/Bun/browser - https://typescript.dpkit.app
dpkit is 10x-100x faster than frictionless-py for tablular validation, showing performance similar to qsv. For example, dpkit takes around 5 seconds to validate a 1GB CSV file. In addition to a spectacular speed, dpkit is based on the rich Data Package validation system compared to JSON Schema based validation used in qsv.
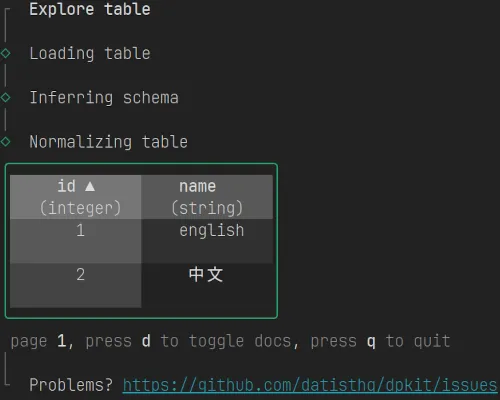
dpkit provides an interactive CLI tool for data wrangling and validation. For example, you can explore a table from a Zenodo dataset with a simple command providing you an interactive interface to the dataset and the table (including sorting and pagination):
dp table explore -p https://zenodo.org/records/7559361dpkit is in its early days and we are looking for feedback and contributions. Please star it on Github to help the project grow - https://github.com/datisthq/dpkit
Special thanks to NLnet for supporting this development!